CS224N Lecture 5 Recurrent Neural Networks and Language Models
Languages modeling and RNNs

语言模型是一个预测下一个词是什么的任务,
the students opened their ________这个就是预测横线上填什么单词,(完型填空……)
更正式地:给定一个单词序列$\boldsymbol{x}^{(1)}, \boldsymbol{x}^{(2)}, \cdots, \boldsymbol{x}^{(t)}$
其中,$\boldsymbol{x}^{(t+1)} $ 是词汇表中的任何一个词。
- 这样做的系统就是语言模型

- 你也可以认为语言模型是一个将概率分配给一段文本系统
- 例如,如果我们有一些文本,那么该文本概率为,如上图。

上面应用中就是输入就会预测提示下一个词。
n-gram Language Models

n-gram 语言模型
定义:n-gram是一段连续词
- unigrams: “the”, “students”, “opened”, ”their” 只来依赖生成位置的前单个词
- bigrams: “the students”, “students opened”, “opened their” 两个词
- trigrams: “the students opened”, “students opened their” 3个词
- 4-grams: “the students opened their” 4个词
想法:收集关于不同n-gram出现频率的统计数据,并用这些数据预测下一个单词。

- 首先,我们做一个马尔科夫假设: 后一个词只取决于前n-1个词
- 问题: 我们怎么得到这些n-gram 和 n-1-gram的概率?
- 答案:通过其在大量文本语料库的数目。
n-gram Language Models: Example

假设我们在学习一个4-gram LM。只要得到:
students opened their w数目students opened their数目
例如,假设在语料库中:
students opened their出现1000次students opened their books出现400次 ,推出其概率为0.4students opened their exams出现100次 ,推出其概率为0.1
那如果文本中出现监考呢?如果出现监考的话, 应该是exam概率比较大的。
Sparsity Problems with n-gram Language Models
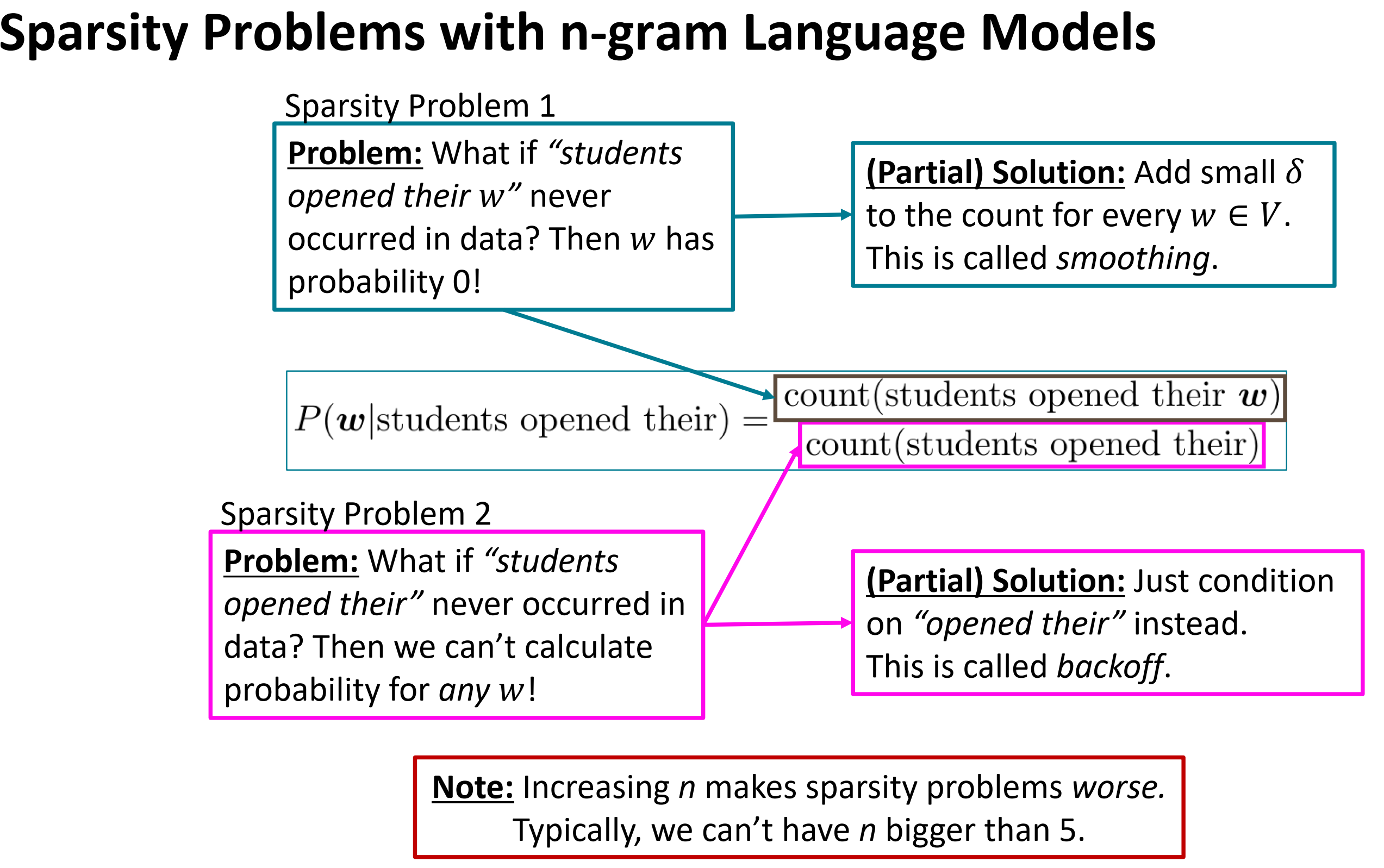
n-gram LM的稀疏问题:
- 问题 :如果
students open their w从未出现在数据中,那么概率值为 0 - (Partial)解决方案 :为每个 $w \in V$ 添加极小数 $\delta$。这叫做平滑。这使得词表中的每个单词都至少有很小的概率。
- 问题 :如果
students open their从未出现在数据中,那么我们将无法计算任何单词 w 的概率值 - (Partial)解决方案 :将条件改为
open their。这叫做backoff。
注意:
增大n会放稀疏问题更严重,通常,我们不能让n大于5.
Storage Problems with n-gram Language Models

增大n就是增大模型大小
n-gram Language Models in practice

可以按照下面网站来试试3-gram LM,language-models
Generating text with a n-gram Language Model


上图中, 依次预测 the price和price of 和后面的词


上图中, 依次预测 today the price of后面的词, 这就生成文本。
How to build a neural Language Model?

- 回忆一下语言模型任务:
- 输入:单词序列
- 输出:在前面词出现的情况下,下一个词出现的概率
- 第三讲中的window-based neural model被应用于命名实体识别问题
A fixed-window neural Language Model
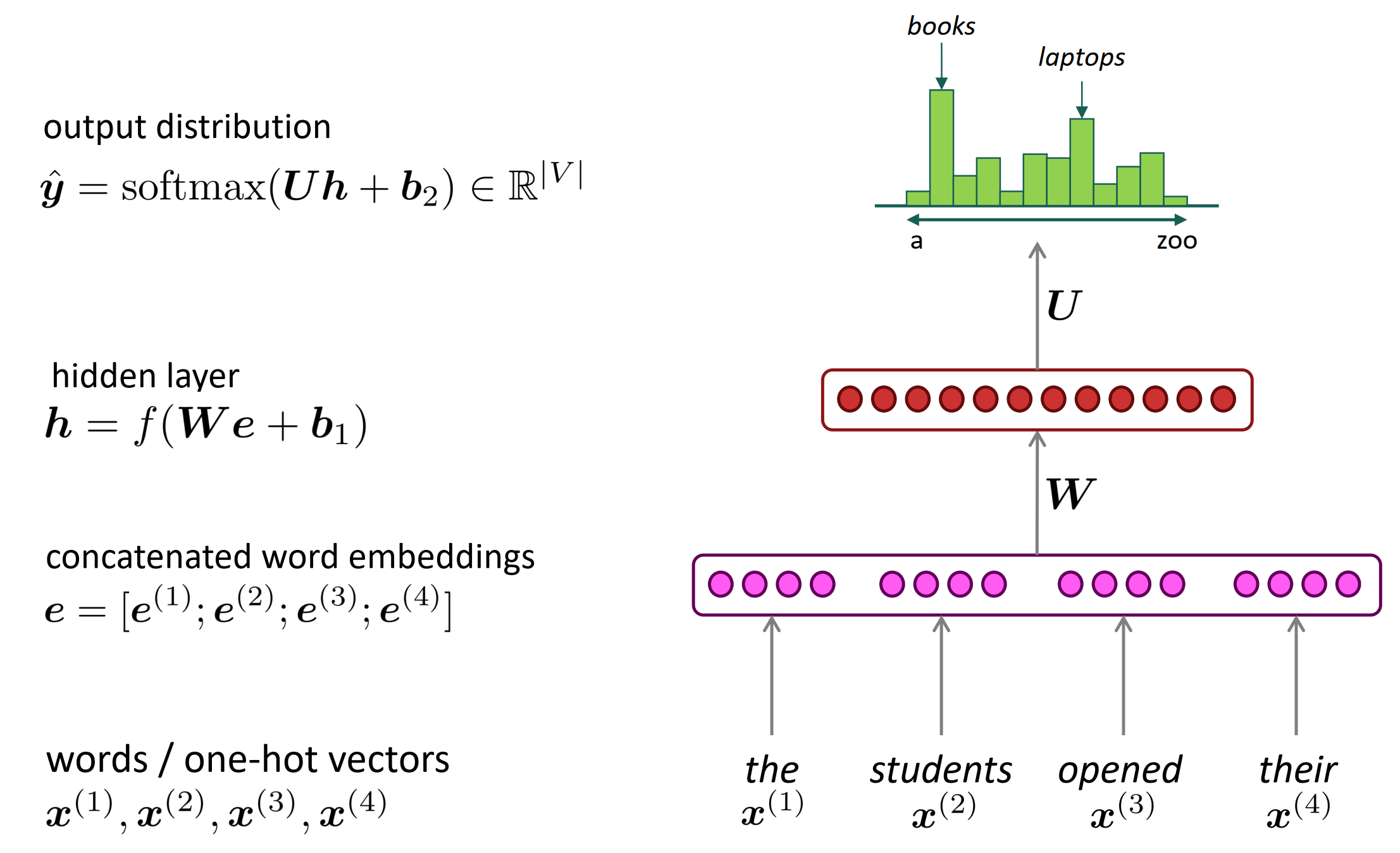
跟命名实体识别问题中一样的网络结构

改进 n-gram LM:
- 没有稀疏问题
- 不需要存储所有观察到的n-grams
存在问题
- 固定窗口太小
- 扩大窗口就需要扩大权重矩阵
- 窗口再大也不够用
- x1和x2乘以不同权重w。处理输入不对称。
需要一个能处理任何长度输入的神经网络结构
固定窗口的神经语言模型相比于n-gram,优点是:
- 不存在稀疏性问题。因为它不要求语料库中出现n-gram的词组,它仅仅是把每个独立的单词的词向量组合起来。只要有词向量,就有输入,至少整个模型能顺利跑通。
- 节省存储空间,不需要存储n-gram的组合,只需要存储每个独立的词的词向量。没有组合爆炸的问题。
依然存在的问题是:
- 固定窗口大小还是太小了,受限于窗口大小,不能感知远距离的关系。
- 增大窗口大小,权重矩阵W也要相应的增大,导致网络变得复杂。事实上,窗口大小不可能足够大。
- 输入$e^{(1)},…,e^{(4)}$对应W中的不同列,即每个e对应的权重完全是独立的,没有某种共享关系,导致训练效率比较低。
RNN

核心想法:重复使用一样的权重W。

RNN结构如上图所示。RNN没有所谓窗口的概念,它的输入可以是任意长度,特别适合对顺序敏感的序列问题进行建模。还是以本文的语言模型
the students opened their为例,介绍一下RNN的内部结构。对于时刻$t$(位置)的输入词$x(t)$来说,首先把它转换为词向量$e^{(t)}$,作RNN真正的输入;然后对于隐藏层,它的输入来自两部分,一部分是$t$时刻的输入的变换$W_e e^{t}$,另一部分是上一刻的隐状态的变换$W_h h^{(t-1)}$ ,这两部分组合起来再做一个非线性变换,得到当前层的隐状态 $h^{(t)}$;最后,隐状态再接一个softmax层,得到该时刻的输出概率分布。需要注意的是,RNN:
- 每一个时刻t都可以有输出,上图仅展示了最后时刻$t=4$时的输出
- $h^{(0)}$是初始隐状态,可以是根据之前的学习经验设置的,也可以是随机值,也可以是全0
- 整个网络中,所有时刻的$W_e, W_h, U, b_1, b_2$都是同一个参数,即不同时刻的权重是共享的,不同的是不同时刻的输入$x^{(t)}$和隐状态$ h^{(t)}$
- 这里的词向量$e$可以是pre-trained得到的,然后固定不动了;也可以根据实际任务进行fine-tune; 在实际任务中现场学习,最好还是用pre-trained的词向量,如果数据量很大的话,再考虑fine-tune 。
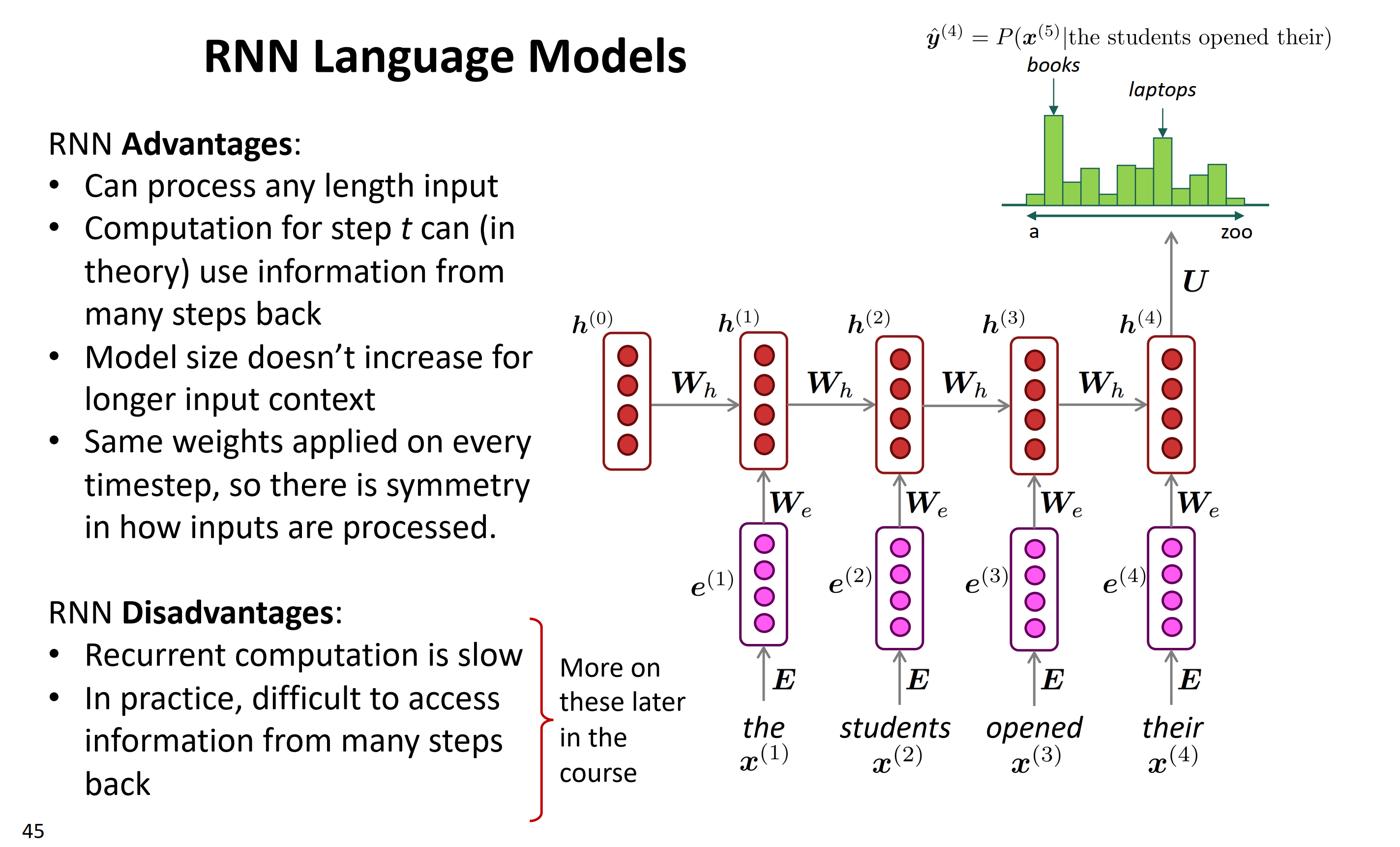
RNN的优点:
- 能处理任意长度输入
- 计算时序t时,能使用许多之前时序的信息(理论上)
- 模型大小不随输入文本长度增加
- 同样权重应用于每个时序,无论处理多少输入这里是对称的
RNN的缺点:
- 循环计算是非常慢的
- 实际上,很难从前面获取信息
RNN相比于固定窗口的神经网络,其优势是:
- 不受输入长度限制,可以处理任意长度的序列
- 状态t可以感知很久以前的状态
- 模型大小是固定的,因为不同时刻的参数$W_e, W_h, U, b_1, b_2$都是共享的,不受输入长度的影响
- 所有参数$W_e, W_h, U, b_1, b_2$是共享的,训练起来更高效
存在的不足:
- 训练起来很慢,因为后续状态需要用到前面的状态,是串行的,难以并行计算
- 虽然理论上t时刻可以感知很久以前的状态,但实际上很难,因为梯度消失的问题
Training an RNN Language Model

- 获取一个大的文本语料,单词$x^{(1)}, \cdots, x^{(T)}$序列
输入进RNN-LM;计算每个step t 上的输出概率分布$\hat y^{(t)}$
- 如给定词,预测到当前的每个词的分布
- 损失函数在step t 是,关于 预测概率$\hat y^{(t)}$和下一个词$\hat y ^{(t)}$之间的交叉熵
- 平均这个交叉熵,得到整个训练集的损失。
训练RNN依然是梯度下降。首先我们需要定义损失函数,RNN在$t$时刻的输出是预测第$t+1$个词的概率分布$y^(t)$;而对于训练集中给定的文本来说,第$t+1$个词是已知的某个词,所以真实答案$y(t)$其实是一个one-hot向量,在第$x(t+1)$位置为1,其他位置为0。所以如果是交叉熵损失函数的话,表达式如上图中间的等式。RNN整体的损失就是所有时刻的损失均值。

如上图中依次获得$J^{(1)}(\theta), J^{(2)}(\theta), J^{(3)}(\theta), J^{(4)}(\theta) $

然而:计算 整个语料库 的损失和梯度太昂贵了
在实践中,我们通常将x 序列 看做一个 句子 或是 文档
- 回忆 :随机梯度下降允许我们计算小块数据的损失和梯度,并进行更新。
- 计算一个句子的损失(实际上是一批句子),计算梯度和更新权重。重复上述操作。
Backpropagation for RNNs

RNN结构,左边是未展开形式,右边是根据时间展开得网络图,注意所有时刻$U, W, V$都是一样的,为了便于里解,输出的由$o$改为$y$.
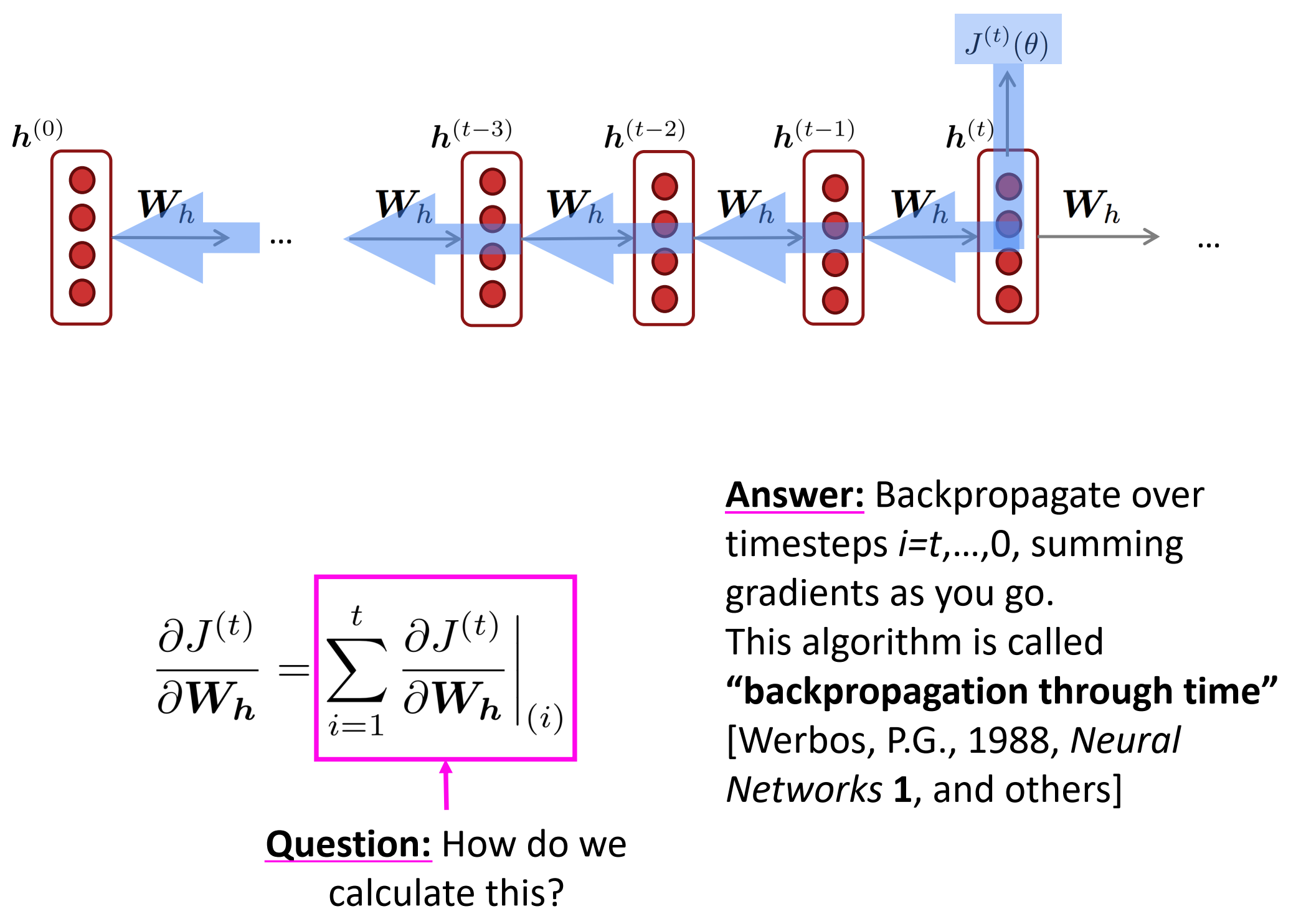
Q: 我们怎么计算损失函数对权重w的梯度?
A: 反向传播遍历时序$t=t, …, 0$,就是之前每个时刻的梯度之和。
Generating text with a RNN Language Model
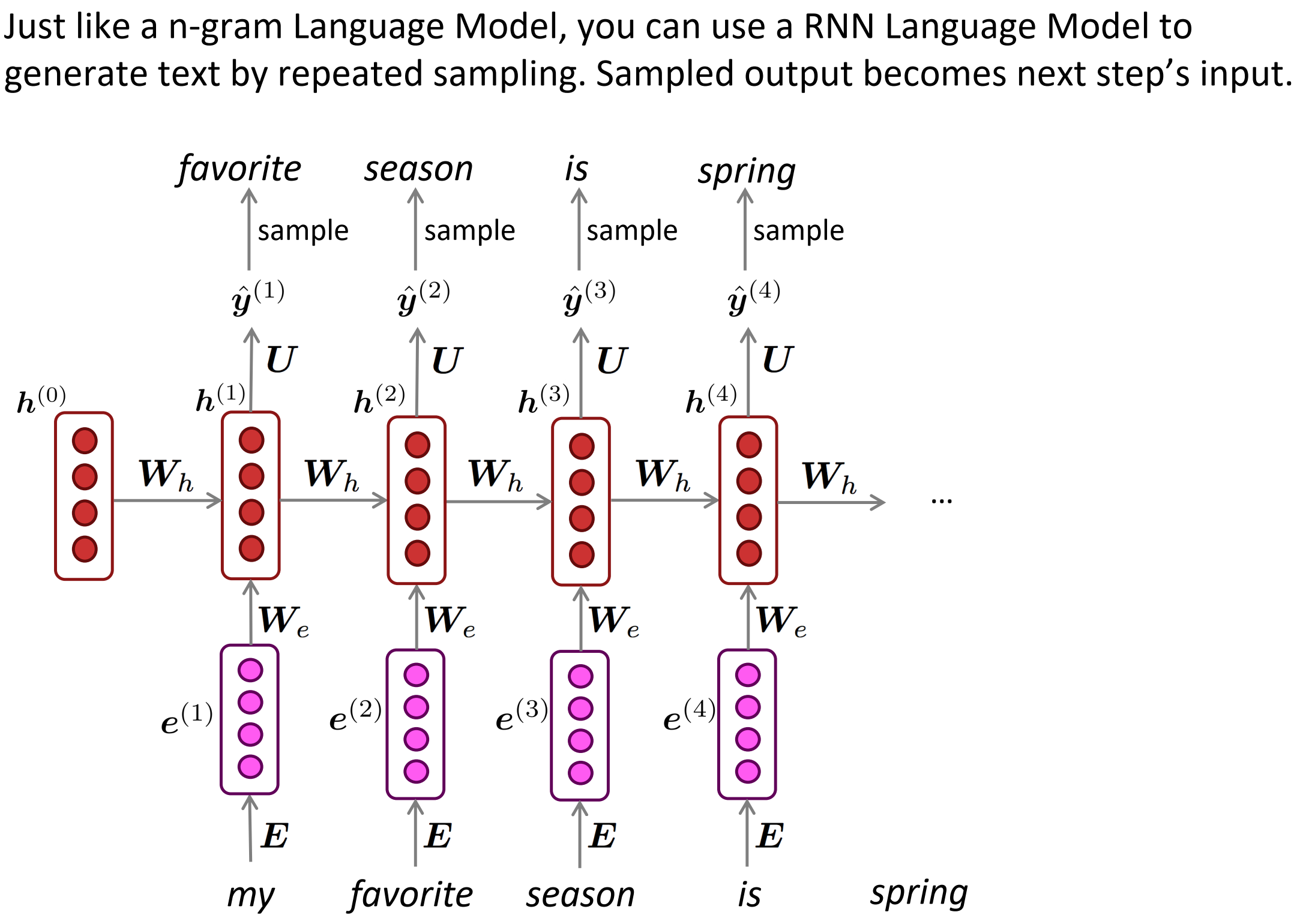
我们也可像n-gram 模型一样通过重复采样生成文本。采样输出变成下一步的输入。


一些RNN-LM有趣的试验,比如生成奥巴马演讲 Obama-RNN和 哈利波特小说。
Evaluating Language Models

- 标准的LM估计指标是perplexity
- 等于交叉熵损失的指数,低perplexity更好!
RNNs have greatly improved perplexity

Why should we care about Language Modeling?

- 语言模型是一项基准测试任务,它帮助我们衡量我们在理解语言方面的进展
- 语言建模是许多NLP任务的子组件,尤其是那些涉及生成文本或估计文本概率的任务
- 预测性打字
- 语音识别
- 手写识别
- 拼写/语法纠正
- 作者识别
- 机器翻译
- 摘要
- 对话
- 等等
Recap

- 语言模型: 预测下一个单词 的系统
- 递归神经网络:一系列神经网络
- 采用任意长度的顺序输入
- 在每一步上应用相同的权重
- 可以选择在每一步上生成输出
- 递归神经网络≠≠语言模型
- 我们已经证明,RNNs是构建LM的一个很好的方法。
- 但RNNs的用处要大得多!
RNN的应用
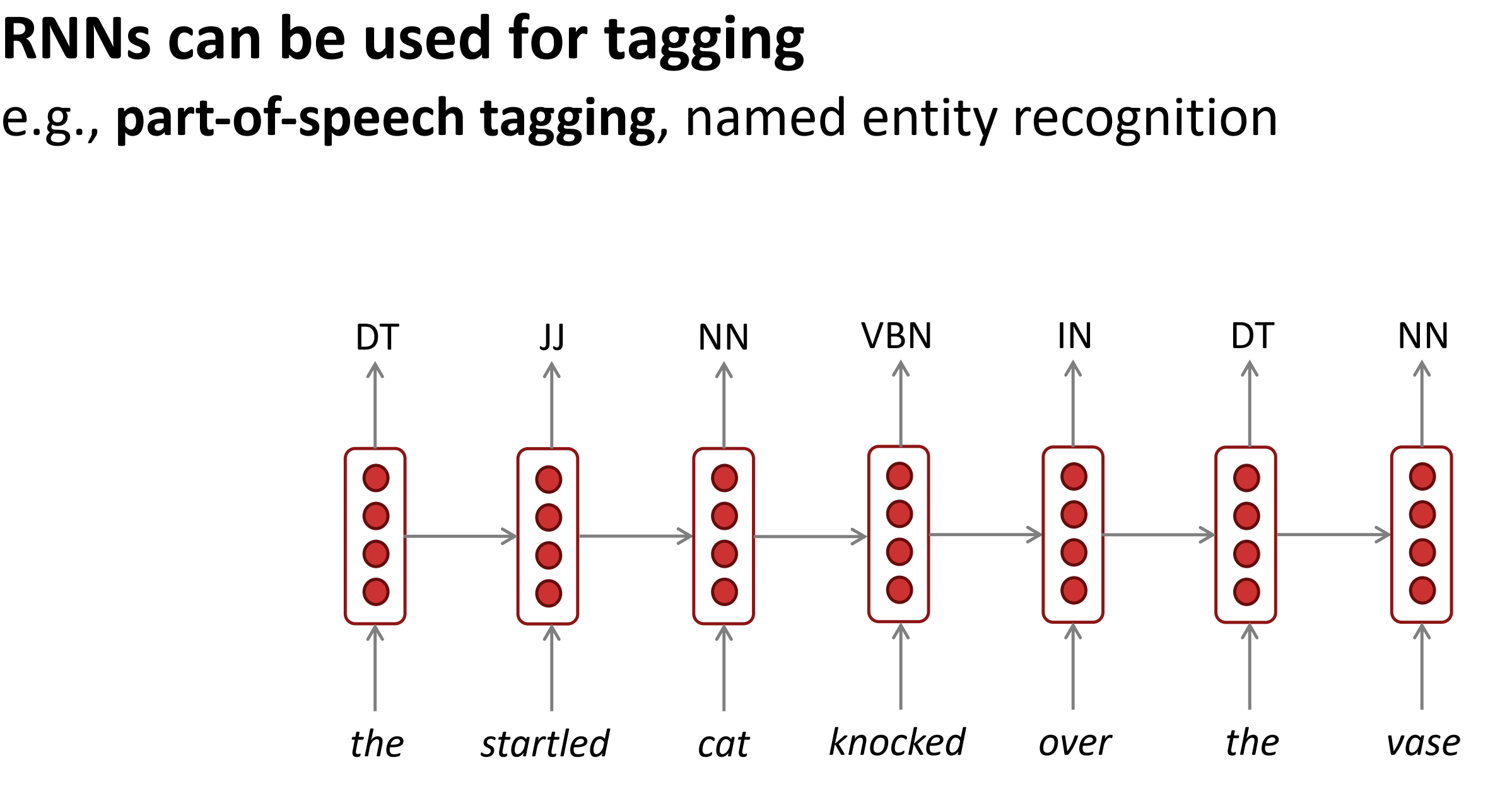
- RNN 用来标注
- RNN用来做句子分类(情感分类等)



基本:用最终的隐层层来编码,使用所有隐层的最大值和均值来做逐元素
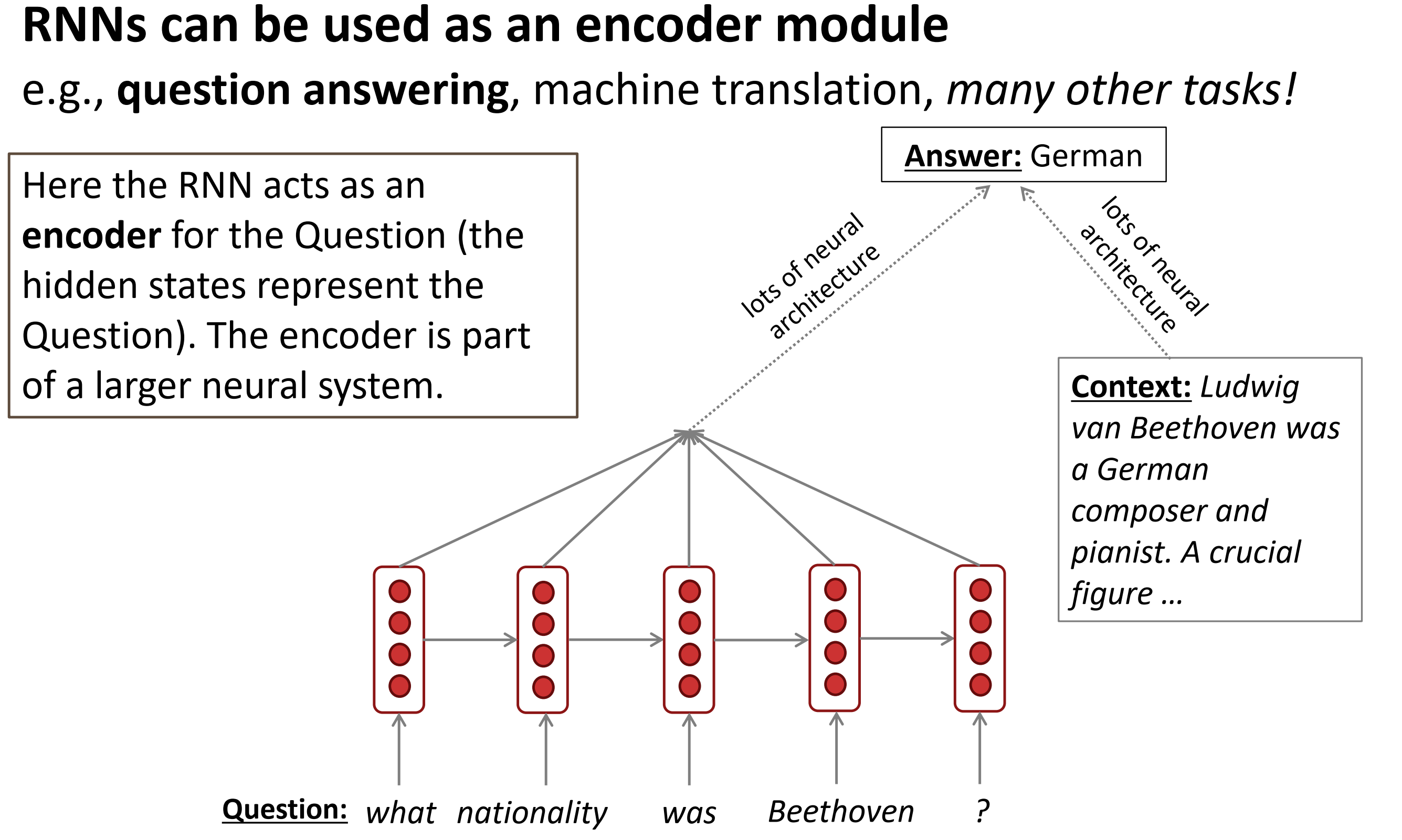
- RNN用来做编码器
编码器和解码器是注意力机制中的一个内容,后续肯定会学习的~,编码器和解码器其实都是RNN实现的(也可能是RNN的变种)
- RNN做文本生成

参考
[1] cs224n-2021-lecture05-rnnlm
[2] cs224n-2019-notes05-LM_RNN
[3] RNN 梯度推导
[4] CS224n 笔记
[5] BPTT
 wechat
wechat alipay
alipay




